|
|
楼主

楼主 |
发表于 2011-10-1 00:29:17
|
只看该作者
Modeling loss given default (LGD) by finite mixture model
From Dapangmao's blog on sas-analysis
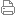
<div class="separator" style="clear: both; text-align: center;"><a href="http://1.bp.blogspot.com/-5Se3iFWv_zk/ToXdRtNXjcI/AAAAAAAAAwo/vNKT703ZXec/s1600/Slide1.JPG" imageanchor="1" style="margin-left: 1em; margin-right: 1em;"><img border="0" height="300" src="http://1.bp.blogspot.com/-5Se3iFWv_zk/ToXdRtNXjcI/AAAAAAAAAwo/vNKT703ZXec/s400/Slide1.JPG" width="400" /></a></div>The 'highly skewed' and 'highly irregular' loss data from the insurance and banking world is routinely fitted by a simple beta/ lognormal/gamma/Pareto distribution. While looking at the distribution plot, I bet that many people don’t want to buy this story and are willing to explore better ways. Finite mixture model that incorporates multiple distributions can be a good option in the radar map. For example, <a href="http://www.sas.com/events/analytics/us/speaker.html">Matt Flynn<span id="goog_917801801"></span><span id="goog_917801802"></span></a> will present how to use PROC NLMIXED to realize finite mixture model for insurance loss data in the incoming SAS ANALYTICS 2011 conference. Finally the revolutionary FMM procedure shipped with SAS 9.3 makes building finite mixture model easy. <br />
<br />
<div class="separator" style="clear: both; text-align: center;"><a href="http://1.bp.blogspot.com/-_MevPmEgqV4/ToXdmSBUMJI/AAAAAAAAAxA/_eEZBzglxk4/s1600/SGPlot13.PNG" imageanchor="1" style="margin-left: 1em; margin-right: 1em;"><img border="0" height="300" src="http://1.bp.blogspot.com/-_MevPmEgqV4/ToXdmSBUMJI/AAAAAAAAAxA/_eEZBzglxk4/s400/SGPlot13.PNG" width="400" /></a></div><br />
<br />
For example, I have a sample loss given default dataset with 317 observations: lgd(real loss given default) is the dependent variable; lgd_a(mean default rate by industry), lev(leverage coefficient by firm) and i_def( mean default rate by year) are independent variables. The kernel distribution is plotted and difficult to be estimated by naked eyes. <br />
<pre style="background-color: #ebebeb; border: 1px dashed rgb(153, 153, 153); color: #000001; font-size: 14px; line-height: 14px; overflow: auto; padding: 5px; width: 100%;"><code>
data lgddata;
informat lgd lev 12.9 lgd_a 6.4 i_def 4.3;
input lgd lev lgd_a i_def;
label lgd = 'Real loss given default'
lev = 'Leverage coefficient by firm'
lgd_a = 'Mean default rate by year'
i_def = 'Mean default rate by industry';
cards;
0.747573451 0.413989786 0.6261 1.415
/* Other data*/
0.748255544 0.607452819 0.3645 3.783
;
run;
proc kde data = lgddata;
univar lgd / plots = all;
run;
data _lgddata01;
set lgddata;
id + 1;
run;
proc transpose data = _lgddata01 out = _lgddata02 ;
by id;
run;
proc sgplot data = _lgddata02;
hbox col1 / category = _LABEL_;
xaxis label = ' ';
run;
</code></pre><div class="separator" style="clear: both; text-align: center;"><a href="http://4.bp.blogspot.com/-kKQ1_ARKBrY/ToXdYKnAA_I/AAAAAAAAAww/9JPg_WP_Tlo/s1600/Slide2.JPG" imageanchor="1" style="margin-left: 1em; margin-right: 1em;"><img border="0" height="300" src="http://4.bp.blogspot.com/-kKQ1_ARKBrY/ToXdYKnAA_I/AAAAAAAAAww/9JPg_WP_Tlo/s400/Slide2.JPG" width="400" /></a></div>What I need PROC FMM to do is to estimate: 1. which distribution is the best from beta, lognormal, and gamma distributions; 2. how many components (ranging from 1 to 10) are the best for each distribution. To automate and visualize the process, I designed a macro. From the plots above, all penalized criterions (AIC, BIC, etc.) indicate that beta distribution is better than the other two. Also the beta distribution has higher Pearson statistic value and less parameter numbers. <br />
<pre style="background-color: #ebebeb; border: 1px dashed rgb(153, 153, 153); color: #000001; font-size: 14px; line-height: 14px; overflow: auto; padding: 5px; width: 100%;"><code>
ods html style = money;
%macro modselect(data = , depvar = , kmin= , kmax = , modlist = );
%let modcnt=%eval(%sysfunc(count(%cmpres(&modlist),%str( )))+1);
%do i = 1 %to &modcnt;
%let modelnow = %scan(&modlist, &i);
ods output fitstatistics = &modelnow(rename=(value=&modelnow));
ods select densityplot fitstatistics;
proc fmm data = &data;
model &depvar = / kmin=&kmin kmax= &kmax dist=&modelnow;
run;
%end;
data _final;
%do i = 1 %to &modcnt;
set %scan(&modlist, &i);
%end;
run;
proc sgplot data = _tmp01;
%do i = 1 %to &modcnt;
%let modelnow = %scan(&modlist, &i);
series x = descr y = &modelnow;
where descr ne :'E' and descr ne :'P';
%end;
yaxis label = ' ' grid;
run;
proc transpose data = _tmp01 out = _tmp02;
where descr = :'E' or descr = :'P';
id descr;
run;
proc sgplot data = _tmp02;
bubble x = effective_parameters y = effective_components
size = pearson_statistic / datalabel = _name_;
xaxis grid; yaxis grid;
run;
%mend;
%modselect(data = lgddata, depvar = lgd, kmin= 1,
kmax = 10, modlist = beta lognormal gamma);
</code></pre><br />
<br />
<div class="separator" style="clear: both; text-align: center;"><a href="http://3.bp.blogspot.com/-qRZYG3LD7gI/ToXdgU2qQQI/AAAAAAAAAw4/7_OdYjEdtB0/s1600/Slide3.JPG" imageanchor="1" style="margin-left: 1em; margin-right: 1em;"><img border="0" height="300" src="http://3.bp.blogspot.com/-qRZYG3LD7gI/ToXdgU2qQQI/AAAAAAAAAw4/7_OdYjEdtB0/s400/Slide3.JPG" width="400" /></a></div>The optimized component number for the beta distribution is 5 – beautiful matching curve. Lognormal distribution exhausted the maximum 10 components and fits the kernel distribution very awkwardly. Gamma distribution used 9 components and fits relatively well. <br />
<div class="separator" style="clear: both; text-align: center;"><a href="http://1.bp.blogspot.com/-WdIau-oKs4c/ToXd-r-_6WI/AAAAAAAAAxI/aU_ZDJOvD3c/s1600/SGPlot25.png" imageanchor="1" style="margin-left: 1em; margin-right: 1em;"><img border="0" height="300" src="http://1.bp.blogspot.com/-WdIau-oKs4c/ToXd-r-_6WI/AAAAAAAAAxI/aU_ZDJOvD3c/s400/SGPlot25.png" width="400" /></a></div><br />
<br />
Then I chose the 5-compenent Homogeneous beta distribution to model the LGD data. PROC FMM provided all parameter estimates for these 5 components. From the plot above, the intercepts and the scale parameter s are different as expected. Interestingly, the parameters of lgd_a(mean default rate by industry) present big diversity, while the parameters of i_def( mean default rate by year) tend to converge at the zero point. <br />
<pre style="background-color: #ebebeb; border: 1px dashed rgb(153, 153, 153); color: #000001; font-size: 14px; line-height: 14px; overflow: auto; padding: 5px; width: 100%;"><code>
ods output parameterestimates = parmds;
proc fmm data = lgddata;
model lgd = lev lgd_a i_def / k = 5 dist=beta;
run;
proc sgplot data = parmds;
series x = Effect y = Estimate / group = Component;
xaxis grid label = ' '; yaxis grid;
run;
ods html style = htmlbluecml;
</code></pre>In conclusion, although PROC FMM is still an experimental procedure, its powerful model selection features would significantly change the way how people feel and use the loss data in the risk management industry.<div class="blogger-post-footer"><img width='1' height='1' src='https://blogger.googleusercontent.com/tracker/3256159328630041416-8207704897250184111?l=www.sasanalysis.com' alt='' /></div><img src="http://feeds.feedburner.com/~r/SasAnalysis/~4/OTvkw_Fz9uk" height="1" width="1"/> |
|